Lo principal para poder salir en resultados de google es que la pagina haya sido rastreada y clasificada por el bots de google, si quieres salir en google o por cualquier otro bot bien yahoo, yandex en rusia o baido en china. Hay quien para ayudar al rastreo añade unos enlaces pero es ya seria link building que podéis ver este otro articulo
Estos bots son capaces de rastrear toda tu web, todos los días, pero lo van hacer en función de un rango de rastreo que te den, todas las web tienen su propio crawl buget o crawl rate como ya nos digo matt cutts en 2010 ” EL numero de paginas que rastreamos es aproximadamente proporcional a su PageRank”
Pero esta no es la única variable para rastrear una web también afecta:
Lo que tarda en cargar el host, el numero de conexiones que permite un host y las paginas que hay alojadas en el.
Que el contenido no sea duplicado, hay que tener muy en cuenta el seo on page y crear contenido de calidad, ya que google por ejemplo es capaz de detectar dicho contenido, en estos casos termina escaneando solo la url que el elige como la buena. También recomienda en esos casos de contenido duplicado hacer una redireccion 301 y de no poderse por ser una combinación de talla o de color, hacer por lo menos un canonical.
Entre la serie de trabas que hace que un bot baje la frecuencia de rastreo estarian.
las urls poco accesibles
Como ya hemos dicho antes que la web tenga muchas paginas duplicadas, con contenido poco util que no aporte ningun valor o inservibles.
Porcentaje alto de urls con errores (4xx, 5xx, 7xx) o muchas redirecciones(3xx).
Tiempos de descargas del html muy altos, se considera alto rangos superiores a los 500ms.
Google como empresa con recursos limitados, fomenta que los webmaster produzcan paginas de calidad, con poco peso, en buenas maquinas y sin errores para que sus robots puedan llegar al maximo de paginas posibles.
Es normal si miramos datos de cuantas webs hay en 2016 ya que se estima que son 1.000 millones cuando en 2013 solo habian 620 millones. Con este crecimiento es normal que google adopte estas medidas, es la única forma de poder tener todas las web actualizadas en un futuro.
En cualquier url de vuestra web podréis ver el numero de veces que es rastreada por el bot y el trafico que recibe, es facil ver como las paginas que mas se rastrean por google son las urls que mas trafico reciben.
Si necesitas mas información podéis ver en el blog de Natzir como funciona a la patente de Percolator y toda la documentación sobre el tema.
Una de las mejores formas de ver la información de rastreo no la ofrece google search console el antiguo google webmaster tools
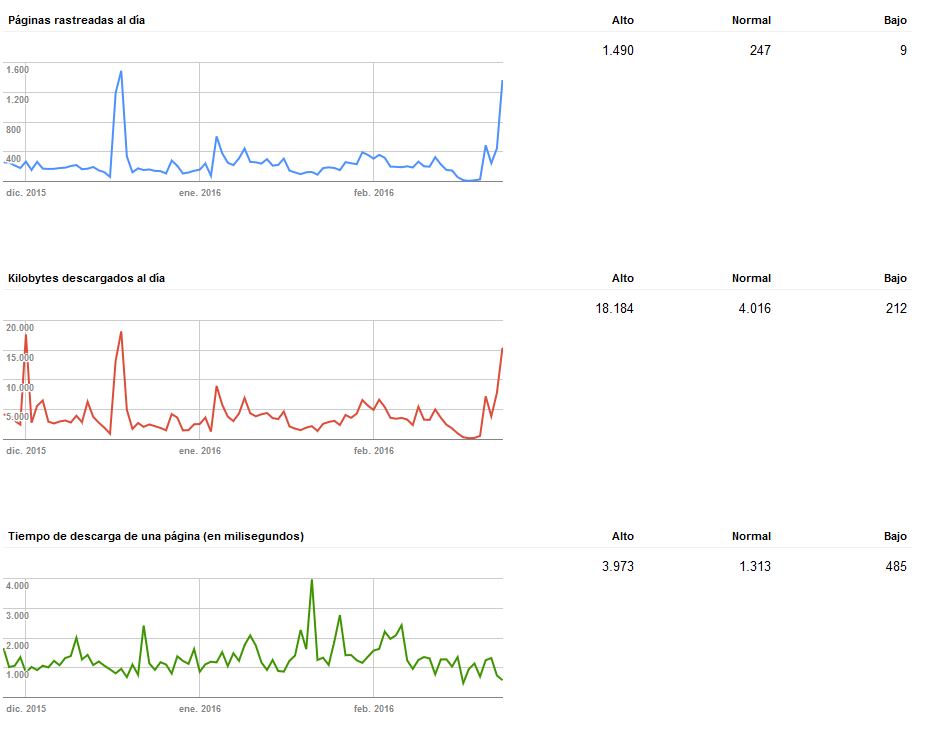
desde ahí se puede ver fácilmente los errores de rastreo para identificar los fallos 404 por ejemplo y en estadísticas de rastreo, ver la cantidad de paginas que se están rastreando, los kilobytes de descarga y la velocidad de descarga.
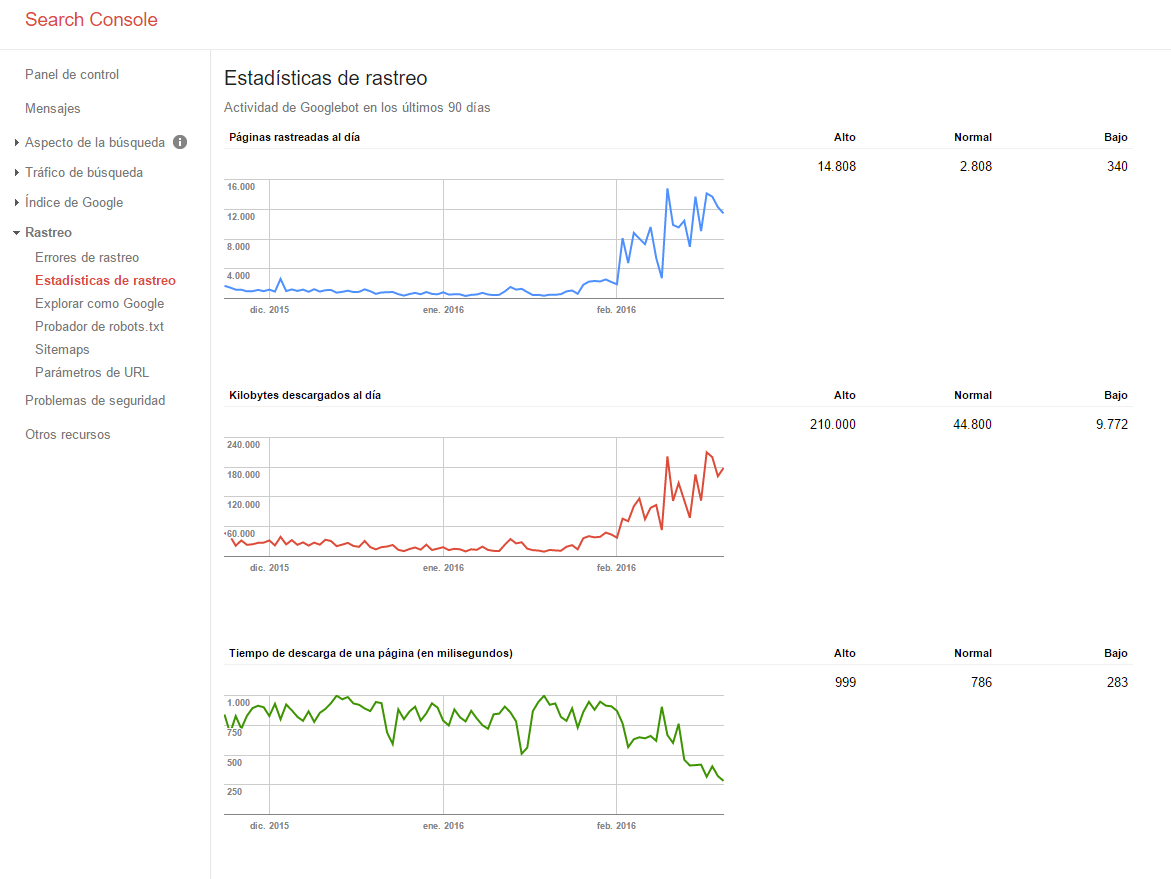
En esta imagen se pude ver como mejorando el tiempo de descarga de una web google rastrea muchas mas url y descarga un volumen mayor de kilobytes, en este ejemplo en concreto no se modifico solo la velocidad del servidor también se solucionaron muchos errores 404 que tenia la web.
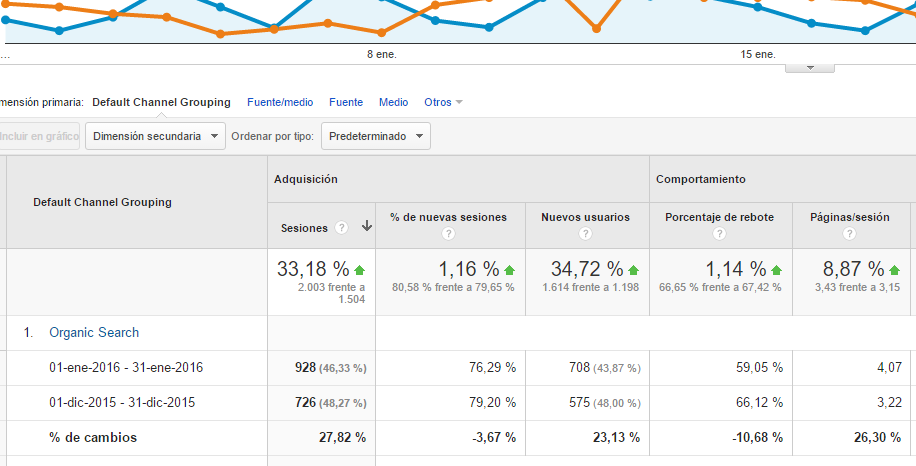
Si comparamos en el mismo periodo google analytics se puede ver el incremento de trafico gracias al mejor crawl rate de la pagina.
Ejemplo de otra web en la que se a mejorado el tiempo de descarga de pagina